🌐 3장. 웹을 구현하는 기술
3.1 웹을 구성하는 구조
3.1.1. 웹과 네트워크
웹(web)은 World Wide Web(WWW)이라는 인터넷에서 제공되는 하이퍼텍스트 시스템이다. 인터넷이라는 표현은 흔히 웹을 가리키지만, 정확히 말해 웹은 인터넷의 한 기능일 뿐이다.
하이퍼텍스트란 문서 안에 다른 문서의 위치 정보를 포함시켜 정보를 서로 연관 지어(하이퍼링크) 참조할 수 있게 만든 문서이다. 이 개념을 인터넷상에서 실현한 것이 웹이다.
웹은 HTML로 대표되는 하이퍼텍스트 언어와 네트워크의 네트워크인 인터넷이 융합되어 탄생하였다.
당초에는 문자 정보만 주고받는 단순한 기술이었지만, 웹 서버에서 동작하는 애플리케이션이나 HTML 언어 자체의 사양이 확장되면서 이용 범위가 확대되었다. 지금은 전자상거래, 온라인 뱅킹, 게임, 동영상 서비스 등 다양한 용도로 활용된다.
3.1.2. 클라이언트와 서버
웹으로 제공되는 서비스 대부분은 서비스를 제공하는 쪽(서버)과 서비스를 받는 쪽(클라이언트)으로 나뉜다. 이를 클라이언트 서버 모델이라고 한다. 서버에 시스템을 설치하고 사용자는 클라이언트에서 서버에 액세스한다.
웹 서비스를 예시로, 서버는 그 역할의 성격상 유지 보수를 해야 하기 때문에 일시적으로 멈출 수 있지만, 기본적으로 언제든지 클라이언트 요구에 대응할 수 있도록 24시간 365일 가동해야 한다.
반면 클라이언트는 서비스를 이용할 때만 동작해야 한다. 사용하지 않을 때는 전원을 끌 수 있으며, 항상 동작하는 것은 아니다. 또 인간이 사용하므로 편의성이나 휴대성 같은 것을 고려해서 만들고 있다.
3.1.3. 웹 서버
웹은 클라이언트 서버 모델을 기반으로 하는 시스템으로, 정보 제공자가 웹 서버를 공개하고 사용자가 웹 브라우저를 통해 웹 서버에 있는 정보에 액세스 하는(브라우징) 형식을 기본으로 한다.

웹 서버는 정보를 전송하거나 서비스를 제공하려고 365일 계속해서 동작하는 컴퓨터를 의미한다. 아파치(Apache)나 엔진엑스(Nginx)처럼 컴퓨터상에서 웹 서버 기능을 제공하는 구체적인 애플리케이션을 가리켜 웹 서버로 지칭할 때도 있으니 주의해야 한다.
웹 서버의 가장 기본적인 역할은 웹 페이지를 공개하는 것이다. HTML로 작성된 문서를 인터넷에 공개하는 역할을 담당한다. 웹 서버에서 애플리케이션을 실행할 수 있는 CGI(Common Gateway Interface) 기술로 인터넷에서는 정보를 양방향으로 교환하게 되었다. 현재는 서버 사이드 언어나 데이터베이스 등과 연계하여 웹에서 많은 일을 할 수 있게 되었다.
3.1.4. HTTP와 HTTPS
HTTP는 서버와 클라이언트 사이에서 데이터를 주고받는 프로토콜이다. 웹이 처음 만들어질 당시에는 정보 공유를 목적으로 한 시스템이었기 때문에 통신 경로에서 정보를 감출 필요가 없었다. 그러나 이용 범위가 확대되면서 웹 서버에 데이터를 전송할 때는 암호화하여 정보 기밀성을 확보할 필요가 생겼다. 그래서 만들어진 것이 HTTPS 프로토콜이다.
HTTPS는 SSL/TLS 구조로 구현되었다. SSL(Secure Sockets Layers)과 TLS(Transport Layer Security)는 인터넷에서 통신을 암호화하여 제삼자가 통신 내용을 훔쳐보거나 조작할 수 없게 하는 기술이다.
SSL은 넷스케이프가 개발한 프로토콜이고, TLS는 SSL을 계승하여 IETF라는 표준화 조직의 TLS 워킹 그룹에서 책정한 프로토콜이다. 현재는 SSL 이 아닌 TLS가 사용되고 있어 TLS라고만 표기해도 되지만, 여전히 SSL 지명도가 높기 때문에 SSL/TLS로 병기하거나 그냥 SSL이라고 할 때도 많다.
3.1.5. SSL 인증서
SSL/TLS를 웹 사이트에서 이용하려면 SSL인증서가 필요하다. SSL 인증서란 인증 기관(CA, Certification Authority)이라는 신뢰할 수 있는 제삼자 기관이 이용자(도메인 소유자)에게 발행하는 것이다.
SSL 인증서의 역할
SSL인증서는 다음 세 가지 목적으로 이용한다.
- 데이터 암호화:
- SSL 인증서에 포함되는 공개 키를 사용함으로써 암호화 통신을 위한 비밀키를 안전하게 교환할 수 있고, 암호화 통신을 실현할 수 있다.
- 도메인 소유 증명:
- SSL 인증서로 해당 도메인은 A가 소유하는 도메인이라는 것을 제삼자인 인증기관에서 보증한다.
- 데이터 변조 방지:
- 제삼자 기관이 보증하는 인증서로 암호화된 통신은 변조되지 않고 확실하게 A의 정보임을 보증한다.
인증 기관 신뢰
인증 기관은 인증 기관 운영 규정이라는 문서를 공개하여 보안 정책을 규정하고, 본사를 둔 국가의 정부 등이 이 문서를 인증함으로써 우리는 인증 기관을 신뢰할 수 있다.

인증 레벨에 따른 종류
SSL 인증서는 인증 레벨에 따라 도메인 인증(DV), 기업 인증(OV), EV인증(EV) 세 가지로 나눌 수 있다. 모든 인증서가 SSL/TLS을 이용한 암호화 통신 기능을 제공하지만, 인증서를 발행하는 조직이 실제로 있는지를 증명하는 범위에는 차이가 있다.
- 도메인 인증(DV, Domain Validation)은 도메인에 등록된 등록자를 확인하고 발행하는 인증서이다. 도메인 소유만 확인할 뿐 도메인 및 인증서 소유자를 인증하는 것은 아니다. 발행 속도가 빠르고 가격이 저렴하여 개인 사이트뿐만 아니라, 기업체, 각종 미디어 등에 폭넓게 이용된다. 특히 개인정보나 신용 카드 정보 등 민감한 정보를 주고받지 않고, 검색 엔진 최적화(SEO, Search Engine Optimization) 이유로 항상 SSL을 적용해야 하는 웹 사이트에서 도메인 인증서를 많이 사용한다.
- 기업 인증(OV, Organization Validation)은 도메인과 더불어 웹 사이트를 운영하는 조직의 실재성을 인증하는 인증서이다. 인증서 발행처가 운영 조직의 실재성을 인증하기 때문에 개인 정보나 신용 카드 정보 등 민감한 정보를 주고받는 웹 사이트 등에 이용된다.
- EV 인증(EV, Extrended Validation)은 기업의 실재성과 더불어 소재지를 인증한다. 인증서로 웹 사이트 운영 조직을 확인할 수 있다. 기업의 실재성을 인증한다는 점에서 기업 인증(OV)과 같다고 생각할 수 있다. 그러나 소재지 확인 등 더욱 엄격한 심사를 거치고 시각적으로도 확인할 수 있어 개인 정보나 신용 카드 정보 등 민감한 정보를 주고받는 웹사이트와 온라인 뱅킹 및 금융 기관과 연계되는 핀테크(Fintech) 서비스를 제공하는 웹 사이트 등에 이용된다.
| 도메인 인증 | 기업 인증 | EV인증 | |
| 암호화 통신 | O | O | O |
| 도메인 소유자 확인 | O | O | O |
| 조직의 실재성 확인 | X | O | O |
| 와일드카드 인증서 대응 | O | O | X |
| 발행 대상자 | 개인, 법인 | 법인 | 법인 |
| 가격 | 6,900원/년~ | 49,000원/년 | 400,000원/년~ |
| 신뢰성 | 낮음 | 중간 | 높음 |
| 용도 | 1. 질문 폼이나 캠페인 응모 등 각종 폼 2. 개인 정보 입력은 하지 않는 웹 사이트의 상시 SSL화용 |
1. 개인 정보 입력이 필요한 회원제 사이트 2. 신용 카드 정보나 개인 정보 입력이 필요한 EC 사이트 |
1. 개인 정보 입력이 필요한 회원제 사이트 2. 신용 카드 정보나 개인 정보 입력이 필요한 EC 사이트 3. 기업 사이트, 온라인 뱅킹 |
| 장점 | - 개인도 이용할 수 있음. - 1년에 1만 원이 안되는 인증서도 있는 등 낮은 가격 - 신청에서 발행까지 속도가 빠름 |
- 조직 실재성을 증명 - 와일드카드 인증서를 발행할 수 있음. |
- 조직 이름이 표시되어 사이트 신뢰성이 향상 |
| 단점 | - 조직 실재성을 증명하지 않음 | - 조직의 실재성을 증명하지만, 브라우저상 표시 기능이 없음 | - 와일드카드 인증서를 발행할 수 없음 - 비교적 고가 |
3.1.6. URL과 DNS
URL
URL(Uniform Resource Locator)은 인터넷상에서 HTML이나 이미지 등 리소스 위치를 특정할 수 있는 서식으로 탄생했다. URL의 기본 서식은 스킴(프로토콜 + ://)과 서버 주소(또는 호스트 이름 + 도메인)에 다음 두 가지를 /로 연결한 것이다.
- 디렉터리 이름
- 파일 이름

DNS
웹 사이트 주소를 http://93.184.216.34/news/index.html처럼 IP 주소로 표기하면 기억하기 어렵다. 호스트 이름과 도메인으로 바꾸어 http://www.example.com/news/index.html로 변경하면 기억하기 쉽고 쓰기도 쉽다.

하지만 인터넷에서는 반드시 IP주소로 접속할 대상을 지정하므로 www.example.com 이 사실을 조회하는 시스템이 필요하다. 이 시스템이 DNS(Domain Name System)이다.
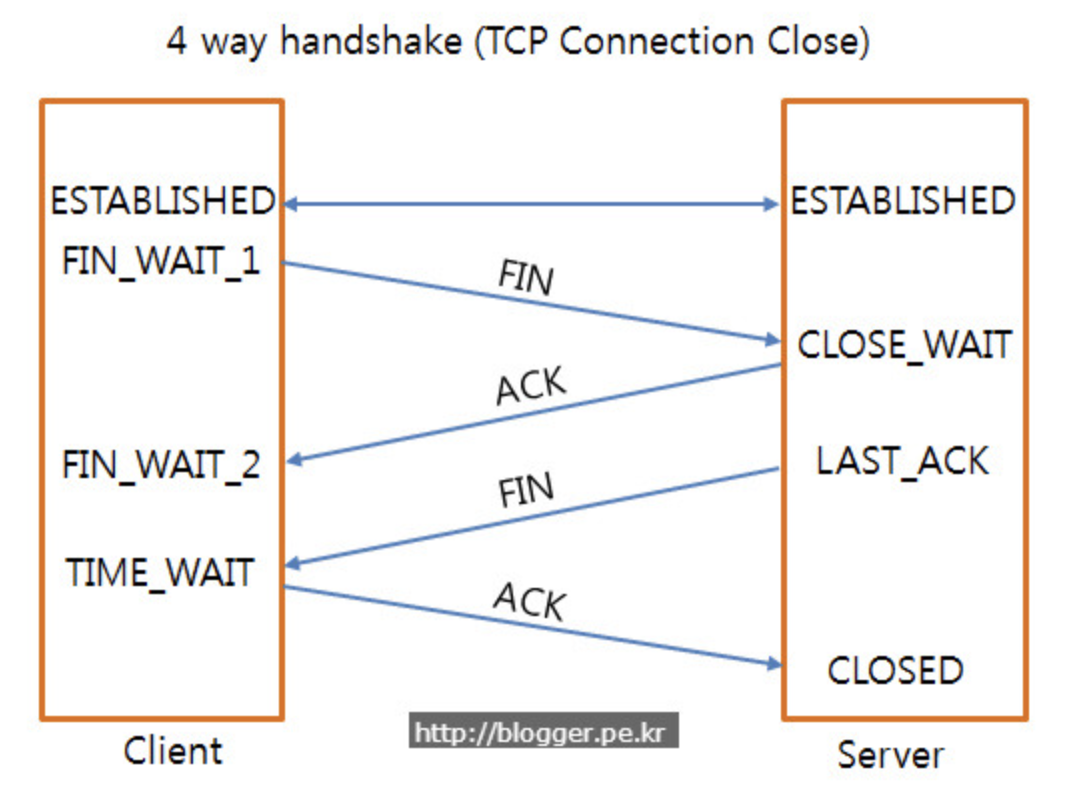
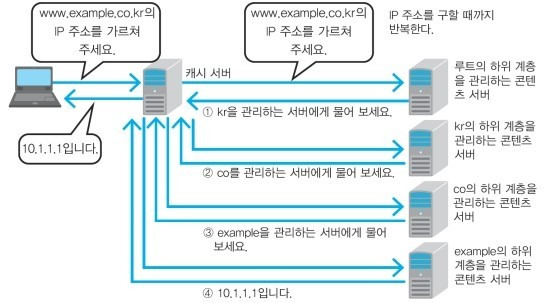
DNS는 인터넷사의 거대한 분산 데이터베이스라고 할 수 있다. DNS는 콘텐츠 DNS서버와 캐시 DNS 서버 두 가지로 구성된다.
콘텐츠 DNS 서버는 각 도메인의 바탕이 되는 기본 정보를 가지고 있고, 캐시 DNS 서버는 컴퓨터나 휴대전화 등 클라이언트가 문의하면 콘텐츠 DNS 서버를 찾아 정보를 요청한다. 캐시 DNS 서버는 콘텐츠 DNS 서버의 조회 결과를 바탕으로 클라이언트에 정보를 전달한다.
3.2. 도메인
도메인이란 인터넷상 주소로, 글로벌 IP주소를 가진 서버가 어디에 있는지 판단하는 정보로 이용된다. 글로벌 IP 주소가 있는 서버는 일반적으로 웹 사이트를 가리킨다.
3.2.1. 도메인 관리 기관
도메인을 전 세계적으로 관리하는 곳은 ICANN이라는 비영리 단체이다. 그 밖에도 도메인을 다루는 조직으로 레지스트리와 레지스트가 있다.
레지스트리는 도메인 관리 기관으로, 각 도메인 정보의 데이터베이스를 관리한다. 레지스트리에 따라서 관리하는 도메인이 달라진다.
레지스트라는 도메인 중개 등록 업체로, 레지스트리가 관리하는 데이터베이스에 직접 도메인 정보를 등록할 수 있다. 도메인을 이용하려면 도메인 이름의 소유자가 누구인지, 어느 DNS 서버에서 관리되는지 같은 정보를 레지스트리 데이터베이스에 기록해야 한다. 이용자가 신청한 정보는 레지스트라를 경유하여 레지스트리의 데이터베이스에 기록된다.

도메인은 레지스트라가 판매하는 것 말고도 레지스트라의 대리점이 판매하는 예도 있다. 국내외로 많은 도메인 판매업자가 있는데 레지스트라가 직접 판매하기도 하고, 레지스트라에서 도메인을 도매로 받아 판매하는 대리점도 있다.
레지스트라는 레지트스리가 관리하는 데이터베이스에 직접 액세스 할 수 있지만, 대리점은 레지스트리가 관리하는 데이터베이스에 액세스할 수 없고 레지스트라를 통해서만 정보를 등록해야 한다.
3.2.2. 도메인 종류
도메인은 크게 두 종류로 나뉜다. gTLD(generic Top Level Domain)와 ccTLD(country code Top Level Domain)이다. 둘 다 ICANN이 관리하지만, 도메인 등록 업무 및 데이터베이스 관리 같은 실제 운영 업무는 레지스트리에 위임한다.
gTLD
gTLD는 전 세계에 등록이 개방된. com,. net,. org와 등록 제한이 있는. edu,. gov,. int,. mil 이렇게 일곱 가지 종류로 시작되었다. 2000년에. biz,. info,. name,. pro,. aero,. coop,. museum 일곱 가지 종류가 추가되었고, 2003년에는. asia,. cat,. jobs,. mobi,. post,. tel,. travel,. xxx가 추가되었다.
2012년부터는 새롭게 창설하는 gTLD 수에 제한을 두지 않고 기술적, 재무적 요건을 충족하는 조직이라면 신청이 가능해져 지금은 매우 많은 gTLD가 존재한다.
일반 이용자도 신청할 수 있는 gTLD 이외에 특정 기업이 전용으로 보유한 gTLD도 있다.
gTLD는 베리사인(Verisign)등의 회사가 레지스트리가 된다.
국내 ICANN인증 레지스트라로는 가비아, 예스닉, 후이즈 등이 있다.
ccTLD(국가 코드 최상위 도메인)
ccTLD는. kr,. us,. uk,. tv 등 전 세계에 200가지 이상이 있으며, 원칙적으로 그 나라에 사는 사람을 대상으로 한다. 하지만 어디까지나 원칙이며, 운영은 각국 네트워크 정보 센처(NIC)에 위임하여 다른 나라 사람에게도 도메인을 개방할 수 있다.
대한민국의 ccTLD는. kr이며, 한국인터넷진흥원(KISA)이 레지스트리로서 운영하고 있다.
. kr의 레지스트라는 가비아, 아이네임즈, 후이즈 등이 있다.
3.2.3. DNS 전환
시스템 전환 작업이나 서버 교체 등 IP 주소가 변경되는 사례는 많이 있다. 이때 DNS 설정도 함께 변경해야 한다.
www.example.com의 IP 주소가 203.0.113.1인 상태가 198.51.1090.1인 상태로 변경해야 하는 경우를 생각해 보자.
원본이 되는 정보는 콘텐츠 DNS 서버가 가지고 있지만, 인터넷상에 여러 개 존재하는 DNS 서버에도 복사된 정보가 있다. (가지고 있지 않은 경우도 있다.) 그리고 캐시 DNS 서버는 한 번 문의한 DNS 정보를 캐시로 보관해 둔다.
캐시 DNS 서버에서 캐시가 사라지고 새로운 정보를 다시 취득할 때 시차가 생긴다. DNS 정보는 스위치처럼 바로 전환할 수 있는 것은 아니고, 새로운 정보가 구석구석 도달하기까지 시간이 걸린다. 원래대로 되돌릴 때도 동일하기 때문에 서버 전환에 실패하고 다시 되돌릴 때도 마찬가지로 시차가 발생한다.
3.3. HTTP와 웹 기술
3.3.1. HTTP
HTTP는 웹 브라우저와 웹 서버 간의 상호 작용을 지원하는 프로토콜이다. HTTP는 데이터를 요청하는 HTTP 요청과 그에 응답하여 데이터를 보내는 HTTP 응답이라는 두 가지 상호 작용을 반복하여 웹 페이지를 표시한다.
HTTP 요청에는 하고 싶은 처리를 나타내는 메서드 이름과 대상 이름이 포함된다.
- GET: 리소스를 가져오도록 웹 서버에 요청
- POST: 웹 서버에 데이터를 송신
- PUT: 웹 서버에 파일을 업로드
HTTP 응답에는 처리 결과를 나타내는 상태 코드와 헤더, 실제 처리 결과인 메시지가 포함된다.
| 상태 코드 | 결과 문구 | 설명 |
| 200 | OK | 요청이 성공했고, 응답과 함께 요청에 따른 정보가 반환된다. |
| 403 | Forbidden | 금지, 액세스 거부, 액세스 권한이 없는 웹 페에지에 접근하는 경우 등 반환된다. |
| 404 | Not Found | 미검출, 웹 페에지를 찾지 못했을때 |
| 408 | Request Timeout | 요청 시간이 초과, 요청이 시간 내에 처리되지 않은 경우 반환 |
| 410 | Gone | 소멸, 리소스가 영구적으로 이동하거나 소멸한다. 웹 페이지가 없어진 것을 대외적으로 나타내는 데 이용한다. |
| 500 | Internal Server Error | 서버 내부 오류, 서버에서 실행 중인 프로그램을 실행하는 데 오류가 발생한 경우 등 반환 |
| 503 | Service Unavailable | 서비스 이용 불가. 일시적으로 과부하 또는 유지 보수로 서비스를 이용할 수 없다. 접속이 몰려 처리 불능에 빠졌을 경우 반환 |
3.3.2. 쿠키와 세션
세션은 웹 사이트를 방문해서 수행하는 일련의 행동이다. HTTP는 데이터를 요청하고 전송하는 상태 비저장 프로토콜이다. 사용자의 '상태'의 관한 정보를 알기 위해 사용하는 것이 쿠키(Cookie)이다. 쿠키란 웹 사이트를 열람한 사용자 정보를 클라이언트가 보관하고, 두 번째 액세스부터는 그 정보를 클라이언트가 서버로 보낸다. 이렇게 하면 다시 방문할 때 사용자를 식별할 수 있어 사용자의 브라우징 특성에 맞는 광고를 제공하거나 사이트 기능에 대한 설정을 저장하여 웹 사이트의 편의성을 높일 수 있다.
세션을 실현하려면 웹 사이트에 접속할 때 세션 ID라는 고유 ID가 할당되어야 한다. 세션 ID를 이용하여 사용자가 누구인지 식별하고, 제품을 추가하는 등의 정보는 세션 ID에 대응하는 세션 변수에 기록된다. 쿠키에 세션 정보를 기록하고, 실제 값(세션 변수 정보)은 서버 측에서 관리하는 방법이 널리 이용된다.
3.3.3. 인증
인증은 컴퓨터나 시스템을 사용할 때 필요한 본인 확인 절차이다. 시스템을 사용할 때 제삼자가 마음대로 사용하거나 제삼자에게 보이지 않도록 하는 인증이라는 메커니즘이 필요하다.
웹에서 인증은 개인 정보를 바탕으로 서비스를 이용하는 것이다. ID와 암호로 인증하는 것이 대부분이지만, 최근에는 다요소 인증(MFA) 이라고 하는 ID와 암호 이외에 일시적으로 발행되는 일회용 패스워드(one-time password)를 입력하는 인증 방식도 있다. 인증 요소를 늘리면 보안이 강화된다. 일회용 패스워드에는 휴대전화 SMS 전송, 전용 일회용 패스워드 생성 소프트웨어 사용, 물리적 하드웨어 토큰 기계에 표시된 암호 등 여러 종류가 있다.
특정 서비스의 자격 증명을 사용하여 다른 서비스에 로그인할 수 있는 위임 인증 메커니즘도 있다. 이 방식에서 사용되는 기술이 OAuth이다.
기업 시스템의 예
한때 기업의 사내 시스템은 시스템마다 ID와 암호 데이터베이스를 가지고 있는 것이 대부분이었다. 그러나 최근에는 Active Directory나 LDAP라는 인증 기반과 연계되어 ID와 암호 하나만 있으면 사내의 어떤 시스템에도 로그인할 수 있다. 물론 시스템마다 권한에 따라 접근을 제한할 필요가 있다.
3.3.4. 새로운 기술: HTTP/2, Ajax, Web API
HTTP/2
HTTP/2는 HTTP의 새로운 규격이다. HTTP의 메이저 버전업으로 기획된 프로토콜로, 그 기반은 구글이 중심이 되어 개발한 SPDY 프로토콜이다.
HTTP/1.1 에서는 동시에 복수의 요청을 보낼 수 있지만, '요청 하나에 응답 하나'라는 기본 구조는 그대로이다. 그래서 HTML 파일 하나와 이미지 파일 여러 개로 구성된 웹 페이지를 표시할 때도 파일 하나마다 GET 요청을 보내야 한다. 이를 포함하여 HTTP/1.1 사양에는 아래와 같은 문제점이 있었다.
- 한 번에 파일 하나밖에 가져올 수 없다: JS, CSS, 이미지 파일 등 많은 리소스를 이용하는 HTML을 로딩하는 데 시간이 걸린다.
- 프로토콜이 텍스트 기반이다: 텍스트 파일(프로그램에서 다룰 수 있는 데이터로 변환)에 시간이 걸린다.
- 파일을 가져올 때마다 거의 같은 HTTP 헤더를 송수신한다: 같은 내용을 송수신하는 만큼 오버헤드가 커진다.
이런 문제점을 받아들여 HTTP/2는 HTTP와 호환성을 유지하면서 새로운 전송 수단을 제공하여 기존 문제점을 해결하고 좀 더 적은 통신량으로 더 신속하게 주고받을 수 있도록 설계되었다.
HTTP/2는 커넥션 하나로 복수 콘텐츠를 병렬로 전송할 수 있어, HTTP/1.1 보다 효율이 높은 프로토콜이 되었다.
HTTP/2로 웹 콘텐츠를 전달하려면 SSL/TLS가 꼭 필요하다고 할 수 있다.
Ajax
웹의 편의성을 높인 것으로 알려진 Ajax라고 하는 프로그래밍 기법이 있다.
Ajax는 이미 읽은 웹 페이지에서 다시 HTTP 요청을 보내 웹 페이지 전환 없이 데이터를 송수신할 수 있는 기능을 제공하는 XMLHttpRequest 기술을 사용한다.
또 XMLHttpRequest로 비동기 통신은 구현할 수 있지만 서버 측에서 푸시 통신을 하는 등 양방향 통신은 어려웠는데, 이를 해결하기 위해 웹소켓(Websocket)이라는 기술도 탄생했다.
Web API
최근에는 각사의 웹 애플리케이션 기능이 Web API로 제공된다. Web API는 사용자 조작과 상관없이 어떤 웹 애플리케이션에서 다른 웹 애플리케이션을 조작할 수 있는 인터페이스이다.
'CS > Network' 카테고리의 다른 글
| [CS-한 권으로 끝내는 네트워크 기초] 5장. 인터넷 서비스의 기반 (0) | 2024.12.03 |
|---|---|
| [CS-한 권으로 끝내는 네트워크 기초] 4장. 네트워크 장비의 종류 (2) | 2024.11.28 |
| [CS-한 권으로 끝내는 네트워크 기초] 2장. 네트워크를 실현하는 기술 (0) | 2024.11.27 |
| [CS-Network] IT(전산) 필기 시험 대비 네트워크 뿌시기👊🏻 (5) | 2024.10.18 |
| [Network] Network 구조와 간단한 용어 정리 (0) | 2024.02.28 |