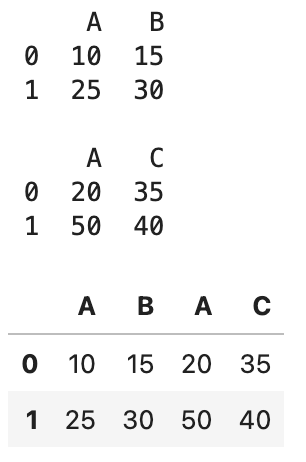
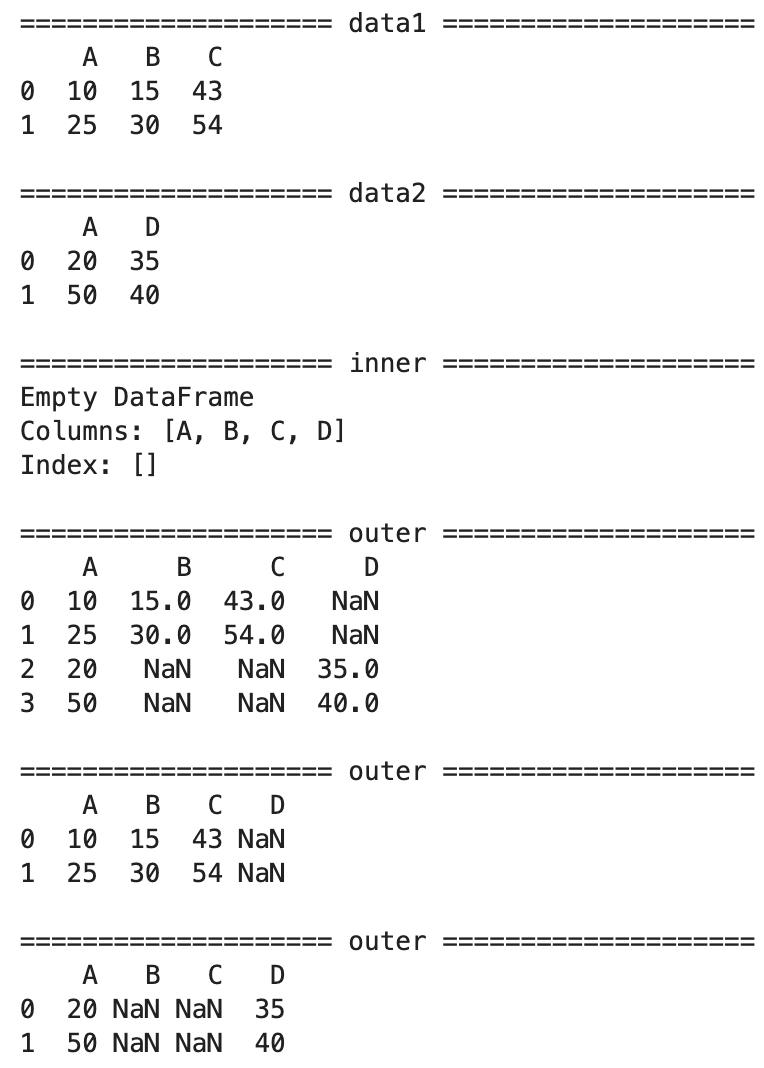
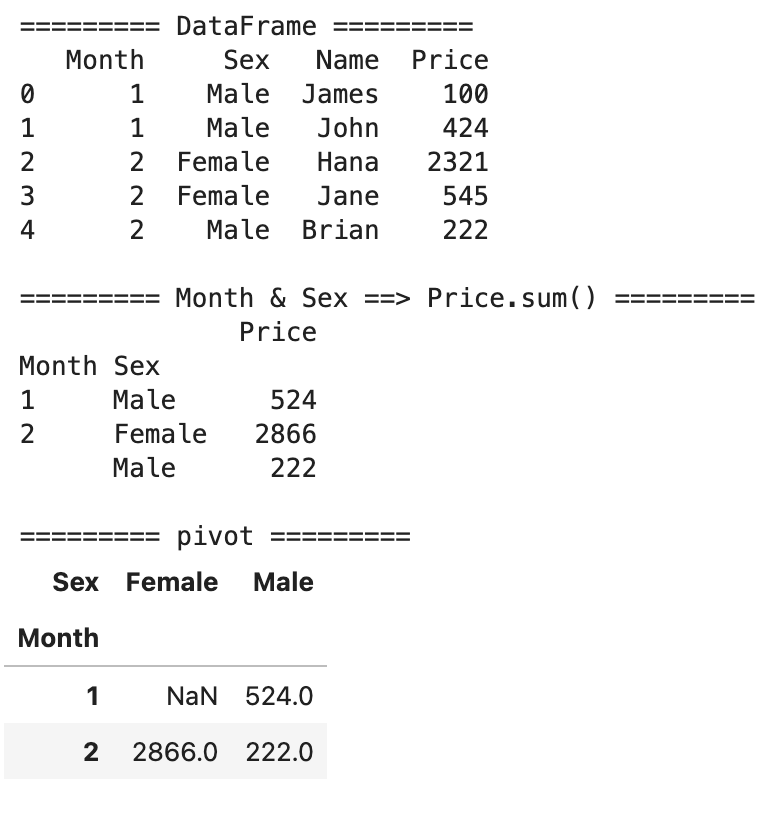
시계열 데이터
시계열 데이터는 행과 행사이에 시간의 흐름(순서)가 있고, 행과 행 사이의 시간간격이 동일한 데이터를 의미한다.
예) 가게의 일별 매출량 데이터
날짜 요소 뽑기
날짜 타입의 변수로 부터 날짜의 요소(일, 월, 주차, ..)를 뽑을 수 있다.
- .dt.날짜 요소
| 메서드 | 내용 |
| df['date'].dt.date | YYYY-MM-DD(문자) |
| df['date'].dt.year | 연(4자리 숫자) |
| df['date'].dt.month | 월(숫자) |
| df['date'].dt.month_name() | 월(문자) |
| df['date'].dt.day | 일(숫자) |
| df['date'].dt.time | HH:MM:SS(문자) |
| df['date'].dt.hour | 시(숫자) |
| df['date'].dt.minute | 분(숫자) |
| df['date'].dt.second | 초(숫자 |
| df['date'].dt.quarter | 분기(숫자) |
| df['date'].dt.day_name() | 요일 이름(문자) |
| df['date'].dt.weekday | 요일숫자(0-월, 1-화, 2-수, ...) (=dayofweek) |
| df['date'].dt.dayofyear | 연 기준 몇일째(숫자) |
| df['date'].dt.days_in_month | 월 일수(숫자) (daysinmonth) |
data = pd.DataFrame([
['2024-02-22', 20153],
['2024-02-23', 20546],
['2024-02-24', 2053],
['2024-02-25', 2033],
['2024-02-26', 2234532],
['2024-02-27', 2653261],
], columns=["Date", "Sales"])
data['Date'] = pd.to_datetime(data['Date'])
print(data['Date'].dt.date) # 각 행 별 날짜 출력
print(data['Date'].dt.year) # 각 행 별 년도 출력
print(data['Date'].dt.month)# 각 행 별 월 출력
print(data['Date'].dt.month_name()) # 각 행 별 월 영어로 출력
print(data['Date'].dt.day) # 각 행 별 일 출력
print(data['Date'].dt.time) # 각 행 별 시간 출력 => 현재 데이터에는 시간이 없어서 00:00:00
print(data['Date'].dt.hour) # 현재 데이터에는 시간이 없어서 0
print(data['Date'].dt.minute) # 현재 데이터에는 시간이 없어서 0
print(data['Date'].dt.second) # 현재 데이터에는 시간이 없어서 0
print(data['Date'].dt.quarter) # 각 행 별 분기
print(data['Date'].dt.day_name()) # 요일 이름 (문자)
print(data['Date'].dt.weekday) # 각 행 별 요일 이름 (숫 자)
print(data['Date'].dt.dayofyear) # 각 행 별 연 기준 몇일째 인지
print(data['Date'].dt.days_in_month) # 각 행 별 월 일수
.shift()
시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 때 사용한다.
data = pd.DataFrame([
['2024-02-22', 20153],
['2024-02-23', 20546],
['2024-02-24', 2053],
['2024-02-25', 2033],
['2024-02-26', 2234532],
['2024-02-27', 2653261],
], columns=["Date", "Sales"])
data['Date'] = pd.to_datetime(data['Date'])
data['sales_lag1'] = data['Sales'].shift() # 하루 전날 데이터 열 추가
data['sales_lag2'] = data['Sales'].shift(2) # 2일 전날 데이터 열 추가
data['sales_lag_1'] = data['Sales'].shift(-1) # 다음 날 데이터 열 추가
data
.rolling().mean()
시간의 흐름에 따라 일정 기간 동안 평균을 이동하면서 구하기
data = pd.DataFrame([
['2024-02-22', 200],
['2024-02-23', 300],
['2024-02-24', 400],
['2024-02-25', 50],
['2024-02-26', 1000],
['2024-02-27', 250],
], columns=["Date", "Sales"])
data['Date'] = pd.to_datetime(data['Date'])
data['sales_mean3'] = data['Sales'].rolling(3).mean() # 3일 동안의 평균
data['sales_max3'] = data['Sales'].rolling(3).max() # 3일 동안의 최대값
data['sales_mean3_min_periods1'] = data['Sales'].rolling(3, min_periods=1).mean() # 3일 동안의 평균을 계산하는데, 하나의 값이라도 존재하면 바로 계산
data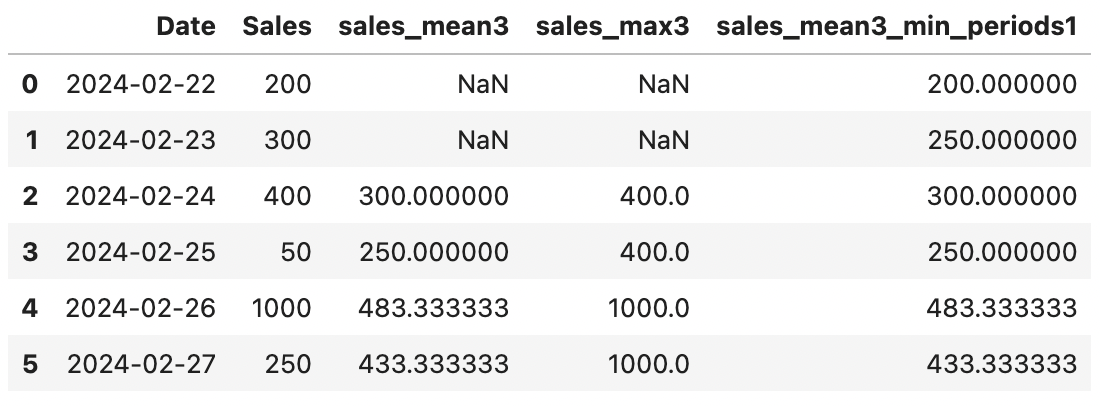
.diff()
특정 시점 데이터, 이전 시점 데이터와의 차이 구하기
- .diff() : 현재 - 하루 전
- .diff(2) : 현재 - 2일 전
data = pd.DataFrame([
['2024-02-22', 200],
['2024-02-23', 300],
['2024-02-24', 400],
['2024-02-25', 50],
['2024-02-26', 1000],
['2024-02-27', 250],
], columns=["Date", "Sales"])
data['Date'] = pd.to_datetime(data['Date'])
data['diff1'] = data['Sales'].diff() # 현재 - 하루 전 값
data['diff2'] = data['Sales'].diff(2) # 현재 - 2일 전 값
data['diff3'] = data['Sales'].diff(3) # 현재 - 3일 전 값
data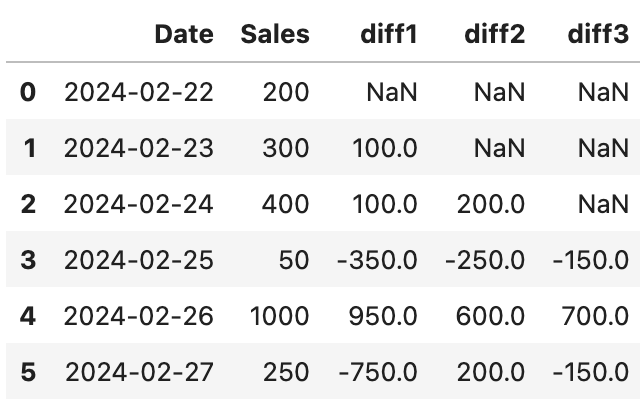
'Language > Python' 카테고리의 다른 글
| [Pandas] 데이터분석을 위한 데이터 전처리 (2) | 2024.03.01 |
|---|---|
| [Pandas] Pandas 기초 (0) | 2024.03.01 |
| [Numpy] Numpy 기초 (0) | 2024.02.29 |
| [Python] List, Dictionary (0) | 2024.02.28 |