IT(전산) 필기 시험 대비 데이터베이스 뿌시기👊🏻
1. KEY
Key란? 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute
1. Candidate Key (후보키)
Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합 (기본키로 사용할 수 있는 속성들)
2가지 조건 만족
- 유일성: Key로 하나의 Tuple을 유일하게 식별할 수 있음.
- 최소성: 꼭 필요한 속성으로만 구성
2. Primary Key (기본키)
후보키 중 선택한 Main Key
특징
- Null값을 가질 수 없음
- 동일한 값이 중복될 수 없음
3. Alternate Key (대체키)
후보키 중 기본키를 제외한 나머지 키 = 보조키
4. Supre Key (슈퍼키)
유일성은 만족하지만, 최소성은 만족하지 못하는 키
5. Foreign Key (외래키)
다른 릴레이션의 기본키를 그대로 참조하는 속성의 집합
2. JOIN
조인이란?
두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
테이블을 연결하려면, 적어도 하나의 칼럼을 서로 공유하고 있어야 하므로 이를 이용하여 데이터 검색에 활용한다.
JOIN의 종류
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- CROSS JOIN
- SELF JOIN
(1) INNER JOIN

교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
INNER JOIN JOIN_TABLE B ON A.NO_EMP=B.NO_EMP
(2) LEFT OUTER JOIN

기준 테이블 값과 조인 테이블과 중복된 값을 보여준다.
왼쪽 테이블 기준으로 JOIN을 한다고 생각하면 편하다
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP=B.NO_EMP
(3) RIGHT OUTER JOIN

LEFT OUTER JOIN과는 반대로 오른쪽 테이블 기준으로 JOIN하는 것이다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
(4) FULL OUTER JOIN
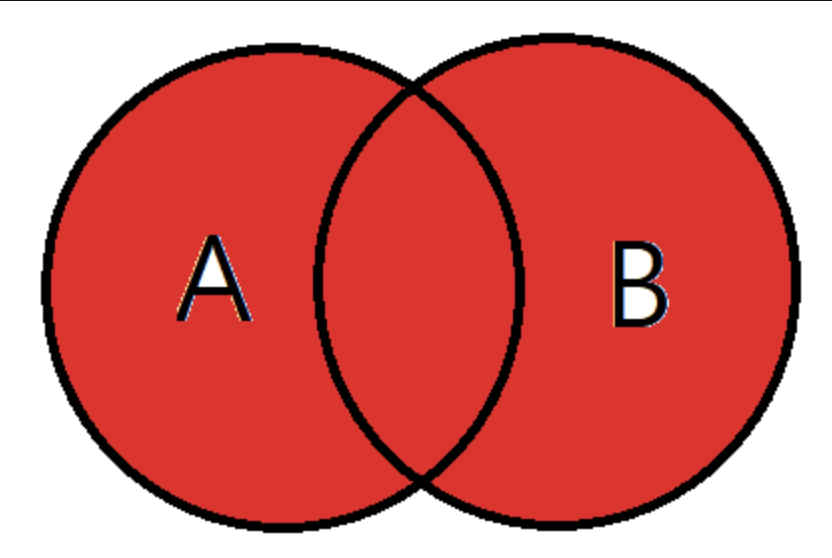
합집합을 말한다. A와 B 테이블의 모든 데이터가 검색된다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
(5) CROSS JOIN

모든 경우의 수를 전부 표현해주는 방식이다.
A가 3개, B가 4개면 총 3 * 4개의 데이터가 검색된다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
CROSS JOIN JOIN_TABLE B
(6) SELF JOIN

자기자신과 자기자신을 조인하는 것이다.
하나의 테이블을 여러번 복사해서 조인한다고 생각하면 편하다.
자신이 갖고 있는 칼럼을 다양하게 변형시켜 활용할 때 자주 사용한다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A, EX_TABLE B
3. SQL Injection
해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법
공격 방법
1) 인증 우회
보통 로그인을 할때, 아이디와 비밀번호를 input 창에 입력하게 된다. 예시로 이해해보자.
아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다.
SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234";
SQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다.
1234; DELETE * USER FROM ID = "1";
보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다.
이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 "1" = "1"과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다.
2) 데이터 노출
시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재이다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다.
즉 예를 들면, 해커는 GET방식으로 동작하는 URL쿼리 스트링을 추가하여 에러를 발생시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다.
방어 방법
1) input 값을 받을 때, 특수문자 여부 검사하기
로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다.
2) SQL서버 오류 발생 시, 해당하는 에러 메시지 감추기
view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다.
3) preparestatement 사용하기
preparestatement를 사용하면, 특수문자를 자동으로 escaping해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 ? 로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다.
4. SQL vs NoSQL의 차이
웹 앱을 개발할 때, 데이터베이스를 선택할 때 고민하게 된다.
MySQL과 같은 SQL을 사용할까? 아니면 MongoDB와 같은 NoSQL을 사용할까?
보통 Spring에서 개발할 때는 MySQL을, Node.js에서는 MongoDB를 주로 사용했을 것이다.
하지만 그냥 다순히 프레임워크에 따라 결정하는 것이 아니다. 프로젝트를 진행하기에 앞서 적합한 데이터베이스를 택해야 한다. 차이점을 알아보자.
SQL(관계형 DB)
SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있음.
관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다.
- 데이터는 관계를 통해 여러 테이블에 분산된다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다. 해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나이다.
또한, 데이터의 중복을 피하기 위해 "관계"를 이용한다.
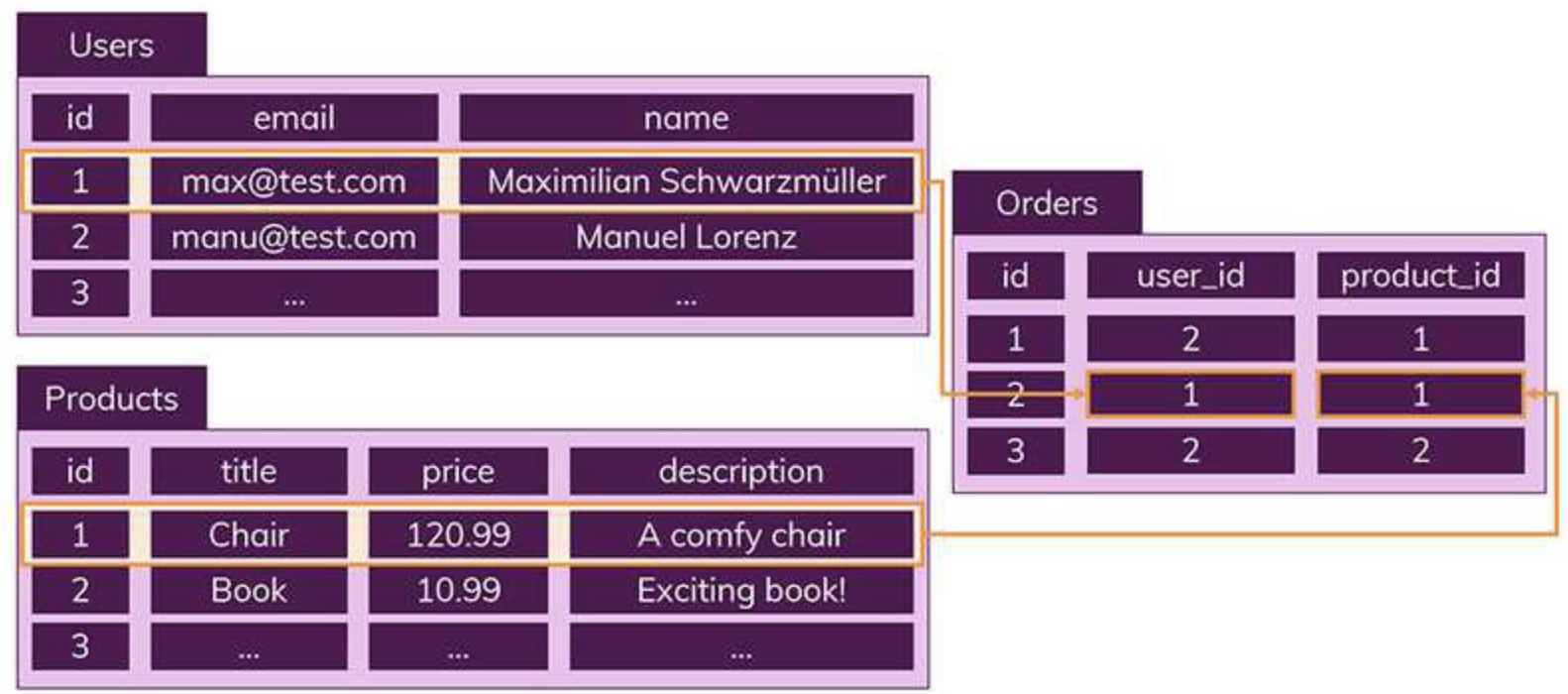
하나의 테이블에서 중복 없이 하나의 데이터만 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
NoSQL(비관계형 DB)
말그대로 관계형 DB의 반대다.
스키마도 없고, 관계도 없다.
NoSQL에서는 레코드를 문서(documents)라고 부른다.
여기서 SQL과 핵심적인 차이가 있는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다. 하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
문서(documents)는 Json과 비슷한 형태를 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다.
따라서 위 사진에 SQL에서 진행한 Orders, Users, Products테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다.
따라서 여러 테이블에 조인할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다. (NoSQL에는 조인이라는 개념이 존재하지 않음)
그러면 조인하고 싶을 때 NoSQL은 어떻게 할까?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.
하지만 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 조인을 잘 사용하지 않고 자주 변경되지 않는 데이터일 때 NoSQL을 쓰면 상당히 효율적이다.
확장 방법
두 데이터베이스를 비교할 때 중요한 Scaling 개념도 존재한다.
데이터베이스 서버의 확장성은 '수직적' 확장과 '수평적' 확장으로 나누어진다.
운여하는 서버의 사용자가 많아질수록 서버에 부하가 증가하여 많은 용량과 성능을 요구하게 된다. 이를 해결하고자 서버를 추가로 설치하는 방법과 기존의 서버의 성능을 높이는 방법이 있다. 서버를 추가로 설치하는 것을 수평적 확장(Scale-Out), 서버의 성능을 높이는 것을 수직적 확장(Scale-Up)이라고 한다.
- 수직적 확장: 단순히 데이터베이스 서버의 성능을 향상시키는 것 (ex. CPU업그레이드)
- 수평적 확장: 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미(하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동)
데이터 저장 방식으로 인해 SQL 데이터베이스는 일반적으로 수직적 확장만 지원함
수평적 확장은 NoSQL 데이터베이스에서만 가능
그럼 둘 중에 뭘 선택?
정답은 없다. 둘 다 훌륭한 솔루션이고 어떤 데이터를 다루느냐에 따라 선택을 고려해야 한다.
SQL장점
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복없이 한번만 저장
SQL단점
- 덜 유연함. 데이터 스키마를 사전에 계획하고 알려야 함. (나중에 수정하기 힘듬)
- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있음
- 대체로 수직적 확장만 가능함
NoSQL 장점
- 스키마가 없어서 유연함. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가 가능
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장됨. 데이터 읽어오는 속도 빨라짐
- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리 가능
NoSQL 단점
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있음
- 데이터 중복을 계속 업데이트 해야 함
- 데이터가 여러 컬렉션에 중복되어 있기 대문에 수정 시 모든 컬렉션에서 수행해야 함.(SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능)
SQL데이터베이스 사용이 더 좋을 때
- 관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션의 경우
NoSQL에서는 여러 컬렉션을 모두 수정해야 하기 때문에 비효율적
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL데이터베이스 사용이 더 좋을 때
- 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우
- 읽기를 자주 하지만, 데이터 변경은 자주 없는 경우
- 데이터베이스를 수평으로 확장해야 하는 경우(막대한 양의 데이터를 다뤄야 하는 경우)
하나의 제시 방법이지 완전한 정답이 정해져 있는 것은 아니다.
SQL을 선택해서 복잡한 JOIN문을 만들지 않도록 설계하여 단점을 없앨 수도 있고
NoSQL을 선택해서 중복 데이터를 줄이는 방법으로 설계해서 단점을 없앨 수도 있다.
5. 정규화 (Normalization)
데이터의 중복을 줄이고, 무결성을 향상시킬 수 있는 정규화에 대해 알아보자
Normalization
가장 큰 목표는 테이블 간 중복된 데이터를 허용하지 않는 것이다.
중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고, DB저장 용량 또한 효율적으로 관리할 수 있다.
목적
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킨다.
- 무결성을 지키고, 이상 현상을 방지한다.
- 테이블 구성을 논리적이고 직관적으로 할 수 있다.
- 데이터베이스 구조 확장이 용이해진다.
정규화에는 여러가지 단계가 있지만 대체적으로 1~3단계 정규화까지의 과정을 거친다.
제 1정규화(1NF)
테이블 컬럼이 원자갑(하나의 값)을 갖도록 테이블을 분리시키는 것을 말하낟.
만족해야 할 조건은 아래와 같다.
- 어떤 릴레이션에 속한 모든 도메인이 원자값으로만 되어 있어야 한다.
- 모든 속성에 반복되는 그룹이 나타나지 않는다.
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.

위 테이블은 전화번호를 여러개 가지고 있어 원자값이 아니다. 따라서 1NF에 맞추기 위해서는 아래와 같이 분리할 수 있다.

제 2정규화(2NF)
테이블의 모든 컬럼이 완전 함수적 종속을 만족해야 한다.
쉽게 말하면, 테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키중 하나의 키만으로 다른 컬럼을 결정지을 수 있으면 안된다.
기본키의 부분집합 키가 결정자가 되어선 안된다는 것
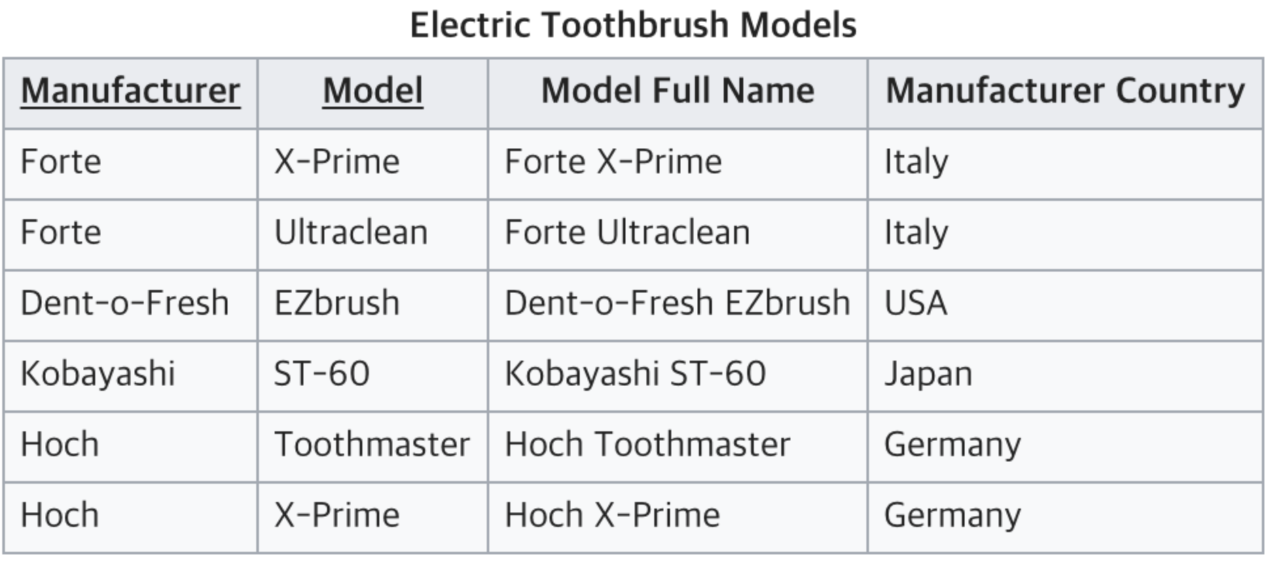
Manufacture과 Model이 키가 되어 Model Full Name을 알 수 있다.
Manufacturer Country는 Manufacturer로 인해 결전된다. (부분 함수 종속)
따라서, Model과 Manufacturer Country는 아무런 연관관계가 없는 상황이다.
결국 완전 함수적 종속을 충족시키지 못하고 있는 테이블이다. 부분 함수 종속을 해결하기 위해 테이블을 아래와 같이 나눠서 2NF를 만족할 수 있다.

제 3정규화(3NF)
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것이다.
이행적 종속: A -> B, B -> C 면 A -> C가 성립된다.
아래 두가지 조건을 만족시켜야 한다.
- 릴레이션이 2NF에 만족하낟.
- 기본키가 아닌 속성들은 기본키에 의존한다.

현재 테이블에서는 Tournament와 Year이 기본키다.
Winner는 이 두 복합키를 통해 결정된다.
하지만 Winner Date of Birth는 기본키가 아닌 Winner에 의해 결정되고 있다.
따라서 이는 3NF를 위반하고 있으므로 아래와 같이 분리해야 한다.

'CS' 카테고리의 다른 글
| [CS-한 권으로 끝내는 네트워크 기초] 1장. 네트워크의 전체적인 모습과 종류 (1) | 2024.10.25 |
|---|---|
| [CS] IT(전산) 필기 시험 대비 Java 뿌시기👊🏻 (5) | 2024.10.17 |