728x90
데이터 처리
데이터 전처리에는 두 단계가 있다.
1. 원본 데이터에서 하나의 데이터셋으로 데이터 구조를 만드는 것 ( 데이터 분석을 위한 전처리 )
2. 모델링을 위한 데이터 전처리 ( ML, DL 모델링 )
이 두 가지 여기서는 데이터 분석을 위한 데이터 전처리하는 방법에 대해 설명할 것이다.
목차
- 데이터프레임 변경
- 데이터프레임 결
1. 데이터프레임 변경
열 이름 변경
- columns 속성 변경
- rename() 메소드 사용
columns
dataframe.columns = update 한 컬럼 이름 리스트
# columns 속성 변경
df.columns = ['name', 'scores', 'age']
rename()
dataframe.rename(columns={"기존 이름" : "변경 이름"})
# rename() 메소드 변경: columns={"기존 이름": "변경할 이름"}
df.rename(columns={'NAME': 'name', 'SCORES', 'scores', 'AGE': 'age'})
열 추가
- df['new column name'] = new column data : 데이터프레임 맨 뒤에 열 추가
- df.insert(index, columnName, value) : 지정한 위치에 열 추가
df['new column name'] = new column data
# df['추가할 열 이름'] = 추가할 열 데이터
# sex = ['Female', 'Male', 'Female', ... ]
df['sex'] = sex
dataframe.insert(index, columnName, value)
# df.insert(index, new_column_name, new_column_data)
sex = ['Female', 'Male', 'Male', ... ]
df.insert(3, 'sex', sex)
열 삭제
df.drop(column_name, axis, inplace )
- column_name: 삭제하고자 하는 열 이름
- axis=0: 행 삭제(기본 값)
- axis=1: 열 삭제
- inplace=True or False
- True: 삭제한 결과를 데이터에 반영
- False: 삭제한 결과를 데이터에 반영하지 않고 삭제한 결과를 조회만.
# 열 하나 삭제
df.drop('column1', axis=1, inplace=True)
# 열 두 개 삭제
df.drop(['column1', 'column2'], axis=1, inplace=True)
값 변경
열 전체 값 변경
# column1의 모든 값을 0으로 변경
df['column1'] = 0조건에 의한 변경
- .loc
- np.where
.loc
# df['column1']의 값이 30보다 큰 경우의 모든 값을 'column1'의 값을 100으로 변경
df.loc[df['column1'] > 30, 'column1'] = 100
np.where(조건문, 참, 거짓)
# column1 의 값이 30보다 큰 경우 100, 아니면 값 그대로
df['column1'] = np.where(df['column1'] > 30, 100, df['column1'])
기존 값을 다른 값으로 변경: map()
# male -> 1, female -> 0
df['sex'] = df['sex'].map({'male': 1, 'female':0})
숫자형 변수를 범주형 변수로 변경: cut()
- pd.cut(df[자를 열 이름], 몇 등분할지, 나눈 값을 어떤 범주이름으로 할지 리스트)
# age열의 값들을 3등분하여 각각 y, m o로 명칭한 값을 age_group 열로 추가
df['age_group'] = pd.cut(df['age'], 3, ['y', 'm', 'o'])2. 데이터 프레임 결합
- pd.concat()
- pd.merge()
pd.concat([target1, target2, ...],axis, join)
concat 메소드는 행 기준으로 결합할지, 열 기준으로 결합할지 지정할 수 있다.
- axis=0
- 행 기준으로 합친다. 즉, 아래나 위로 합친다는 의미이다.
- 열 이름을 기준으로 붙이게 된다.
- join = "outer" ( 기본값 )
- 모든 행과 열을 합친다. (값이 없는 요소는 NaN으로 채운다.)
- join = "inner"
- 같은 행과 열만 합친다.
- axis=1
- 열 기준으로 합친다. 즉, 옆으로 합친다.
- 행 인덱스를 기준으로 붙이게 된다.
- join = "outer" ( 기본값 )
- 모든 행과 열을 합친다. ( 값이 없는 요소는 NaN으로 채운다.)
- join = "inner"
- 같은 행과 열만 합친다.
concat([data1, data2], axis=0, join="outer")
axis=0 행 기준으로 모든 행과 열을 결합 하기 때문에 다음과 같은 결과가 나온다.
data1 = pd.DataFrame([
[10, 15],
[25, 30]
])
data2 = pd.DataFrame([
[20, 35],
[50, 40]
])
pd.concat([data1, data2] ,axis=0, join="outer")

concat([data1, data2], axis=0, join="inner")
data1의 경우 열이 A, B이고, data2의 경우 열이 A, C이기 때문에 열의 이름이 겹치는 A의 값만 결합되게 된다.
data1 = pd.DataFrame([
[10, 15],
[25, 30]
])
data2 = pd.DataFrame([
[20, 35],
[50, 40]
])
data1.columns = ["A", "B"]
data2.columns = ["A", "C"]
print(data1, end="\n\n")
print(data2, end="\n\n")
pd.concat([data1, data2] ,axis=0, join="inner")

concat([data1, data2], axis=1, join="outer")
행의 인덱스를 기준으로 결합을 하는데 모든 행과 열을 합치게 된다.
data1 = pd.DataFrame([
[10, 15],
[25, 30]
])
data2 = pd.DataFrame([
[20, 35],
[50, 40]
])
data1.columns = ["A", "B"]
data2.columns = ["A", "C"]
print(data1, end="\n\n")
print(data2, end="\n\n")
pd.concat([data1, data2], axis=1, join="outer")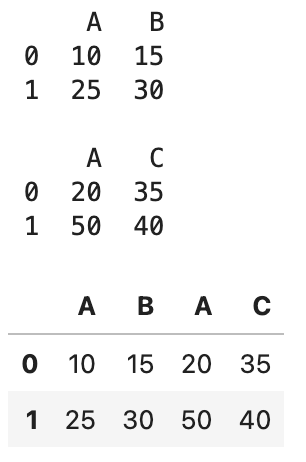
concat([data1, data2], axis=1, join="inner")
data1의 행은 1, 2 data2의 행은 0,1 이 있다.
이중에서 행 인덱스가 같은 값은 1뿐이기 때문에 다음과 같은 결과값이 나온다.
data1 = pd.DataFrame([
[10, 15],
[25, 30],
[32, 54]
])
data2 = pd.DataFrame([
[20, 35],
[50, 40]
])
data1.columns = ["A", "B"]
data2.columns = ["A", "C"]
data1.drop(0, inplace=True)
print(data1, end="\n\n")
print(data2, end="\n\n")
pd.concat([data1, data2], axis=1, join="inner")
pd.merge()
- merge 메소드는 특정 열(key)의 값을 기준으로 결합한다.
- 데이터베이스의 테이블 조인과 같다.
- 옆으로만 결합한다.
- 결합 방법 4가지 ( how )
- inner: 같은 값만
- outer: 모두
- left: 왼쪽 dataframe은 모두, 오른쪽 dataframe 같은 값만
- right: 오른쪽 dataframe은 모두, 왼쪽 dataframe 같은 값만
pd.merge ( inner, outer, left, right ) 한번에 출력
- inner
- 아래 코드에서는 같은 값이 없으므로 출력되는 것이 없다.
- outer
- 모두 다 결합하기 때문에 data1, data2의 모든 A값이 나오게 붙게 되고 빈 값들은 NaN으로 채워진다.
- left
- data1을 기준으로 결합되는데, data2에 data1과 겹치는 값이 없으므로 결과는 data1에 D열이 추가되고, D열에는 NaN으로 채워진다.
- right
- data2를 기준으로 결합되는데, data1에 data2와 겹치는 값이 없으므로 결과는 data2에 B, C열이 추가되고, B, C열에는 NaN으로 채워진다.
data1 = pd.DataFrame([
[10, 15, 43],
[25, 30, 54],
])
data2 = pd.DataFrame([
[20, 35],
[50, 40]
])
data1.columns = ["A", "B", "C"]
data2.columns = ["A", "D"]
print("=" * 20, "data1", "=" * 20)
print(data1, end="\n\n")
print("=" * 20, "data2", "=" * 20)
print(data2, end="\n\n")
print("=" * 20, "inner", "=" * 20)
print(pd.merge(data1,data2, how="inner"))
print()
print("=" * 20, "outer", "=" * 20)
print(pd.merge(data1,data2, how="outer"))
print()
print("=" * 20, "outer", "=" * 20)
print(pd.merge(data1,data2, how="left"))
print()
print("=" * 20, "outer", "=" * 20)
print(pd.merge(data1,data2, how="right"))

pd.pivot_table
- groupby된 데이터를 재구성한다.
- df.pivot_table(index, columns, values)
columnName = ["Month", "Sex", "Name", "Price"]
data = [
[1, "Male", "James", 100],
[1, "Male", "John", 424],
[2, "Female", "Hana", 2321],
[2, "Female", "Jane", 545],
[2, "Male", "Brian", 222],
]
data = pd.DataFrame(data, columns=columnName)
print("========= DataFrame =========")
print(data, end="\n\n")
print("========= Month & Sex ==> Price.sum() =========")
data = data.groupby(['Month', 'Sex'])[['Price']].sum()
print(data, end="\n\n")
print("========= pivot =========")
data.pivot_table(index = "Month", columns = "Sex", values="Price")
1월에 Female 정보가 없기 때문에 NaN이 나온다.

'Language > Python' 카테고리의 다른 글
| [Pandas] 시계열 데이터 처리 (0) | 2024.03.01 |
|---|---|
| [Pandas] Pandas 기초 (0) | 2024.03.01 |
| [Numpy] Numpy 기초 (0) | 2024.02.29 |
| [Python] List, Dictionary (0) | 2024.02.28 |